
Open Table Formats (part-1): Apache Hudi (Hadoop Upserts Deletes and Incrementals)

Introduction
I Have been exploring various table formats recently, And I went deep into Apache hudi. Here is a summary of what I learned from it .
At first, I thought Apache Hudi was simply a way to organize data in tables. But the more I looked into it, I realized it is much more than that. While the functionality provided by a table format is merely one layer in the Hudi software stack, Hudi is a whole system with tools that help manage data more smartly. It is designed to handle big sets of data that are always changing, making it useful for handling large, evolving datasets.
Before diving into Apache Hudi, let's discuss why we need to use a table format instead of directly editing or querying a data set or table.
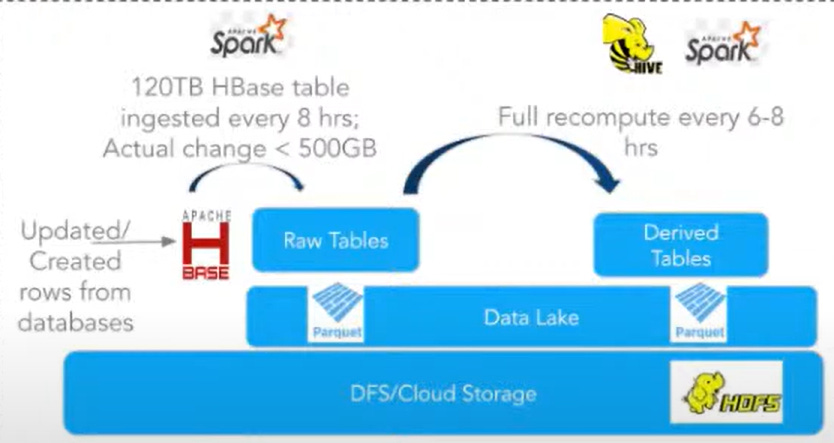
Before Apache Hudi, re-computing a derived or target table after editing or updating data in a source dataset through batch processing was slow and resource-intensive, requiring the entire dataset to be recomputed repeatedly. Additionally, handling late-arriving data was difficult because partitions could not be modified directly, often resulting in the inefficient reprocessing of all data within a partition.
Uber faced similar challenges and developed Hudi to address them. Hudi was later open-sourced and contributed to the Apache Software Foundation.
Apache Hudi is a Transactional Data Lakehouse Platform that brings core warehouse and database functionality directly to a data lake, providing a table-level abstraction over open file formats like Apache Parquet/ORC stored on top of extremely scalable cloud storage or distributed file systems and enabling transactional capabilities such as updates/deletes, making it efficient and easier to organize, store, and work with data, particularly useful for large datasets that are constantly changing. With Hudi's "incremental" data processing, we can update or add new data without having to redo everything.
More than just organizing, and querying the data, It also offers the following capabilities:
Efficient ingestion: Hudi can quickly load data, handling near real-time and stream processing of batch data, which is known as incremental processing, making it very efficient. It supports features like mutability, row-level updates, and deletes.
Efficient reading/writing performance: Hudi can read and write data quickly. It supports features like Merge-Optimized Rows (MOR) tables, indexes, improved file layout, and timeline for optimized data storage and retrieval.
Concurrency control and ACID guarantees: Hudi ensures data consistency when multiple users are accessing the database concurrently. ACID stands for Atomicity, Consistency, Isolation, and Durability, which are crucial for reliable transactions in a database system.
Optimization: Hudi introduced various table optimization services such as cleaning, clustering, compaction and Z-ordering (multi-dimensional clustering)

So, as you can see, the table format is just a slice of the Apache Hudi platform.
Hudi Stack

Apache Hudi is like a smart tool for our data lake, adding features similar to what you find in a database. It creates a table-like structure over your existing data files, making them easier to work with. This means you can now update or delete data, which was not easy before. Hudi also includes important table services that work closely with the database part. These services handle things like keeping track of tables, managing metadata, and organizing how data is stored. With these features, Hudi goes beyond just being a 'table format' and becomes a complete and reliable platform for your data lake.In this overview, we will explore some key components of the Hudi stack. Stay tuned for a deeper dive into the remaining stack components coming soon!
Table Types
Hudi supports the following table types.
Copy On Write (COW) is like using a fancy notebook where you write your notes in pencil, and when you need to update something, you erase and rewrite that part. In the same way, when you store data using COW, you use columnar file formats (like Parquet) and rewrite the entire file with updates.
Merge On Read (MOR) is more like having a notebook where you write your notes with a pen. When you need to update something, you add a note at the bottom saying what you changed. Later, you can combine all these updates to create a new version of your notes. With MOR, you use a mix of columnar and row-based file formats (like Parquet and Avro), and updates are logged separately and then combined to create new versions of your data files.
In simpler terms, COW rewrites the entire file when there's an update, while MOR logs updates separately and then combines them later to create new versions.
Both of these table storage strategies have different strengths based on how they handle reads and writes. Copy On Write (COW) is more suited for read-heavy workloads, meaning it's efficient when you need to retrieve data frequently. This is because COW stores data in columnar formats like Parquet, which are optimized for fast reads.
On the other hand, Merge On Read (MOR) is more suitable for write-heavy workloads, where you're constantly updating or adding new data. MOR uses a combination of columnar and row-based formats (like Parquet and Avro), and it logs updates separately before later combining them to create new versions of the data files. This approach is more efficient for handling frequent writes and updates.
Query Types
After setting up our tables in Hudi, we can use it for different types of queries, depending on what we need to do:
Snapshot Queries: These queries show the latest snapshot of the table as of a specific commit or compaction action. For merge-on-read tables, which combine base and delta files, this provides near-real-time data (within a few minutes). For copy-on-write tables, it offers similar functionality to existing Parquet tables but with additional features like upserts and deletes.
Incremental Queries: These queries only show new data written to the table since a specified commit or compaction. This is useful for building incremental data pipelines, allowing you to process only the changes made to the data.
Read Optimized Queries: These queries also show the latest snapshot of the table as of a specific commit or compaction, but they only expose the base or columnar files in the latest file versions. This ensures that queries maintain the same performance as non-Hudi columnar tables, making them suitable for scenarios where query performance is critical.
See the different query results on different table types.


Hudi Table layout

In Apache Hudi, there are two main types of files: metadata files and data files. Metadata files, found in the .hoodie/ directory, hold important settings for the table and keep track of changes to the data over time. They help us understand what happened to the data and manage how it is updated or deleted.
Data files in Hudi are split into Base Files and Log Files. Base Files store the main data in the table and are great for reading data quickly. They are usually in a format that is good for reading lots of data at once. Log Files, on the other hand, store changes to the data on top of the Base Files and are good for quickly adding new data. Together, these files help us keep track of different versions of our data and see how it's changed over time.
Benefits
Increased Efficiency: Apache Hudi supports record-level updates, reducing computational waste by only reprocessing changed records.
Faster ETL/Derived Pipelines: By using incremental queries, Apache Hudi accelerates data pipelines, processing only incremental changes and updating the target derived table.
Access to Fresh Data: Apache Hudi's approach reduces resource usage and improves performance metrics like query latency, enabling quicker access to data.
Unified Storage: Apache Hudi enables faster and lighter processing on existing data lakes, reducing the need for specialized storage or data marts.
Hudi is built on top of several services and components. We can explore more of that in upcoming blogs.
Recap
Apache Hudi is a smart tool for data lakes. It's more than just organizing data in tables. It helps manage big datasets that are always changing. It can handle updates and deletes easily, and it offers different ways to store and query data. In simple terms, Hudi makes it easier to work with large, evolving datasets.
Ref
https://hudi.apache.org/docs/next/hudi_stack/#lake-storage
https://hudi.apache.org/blog/2021/07/21/streaming-data-lake-platform/
https://www.youtube.com/watch?v=Y7L_ATLacLI&list=PLL2hlSFBmWwz6Q7et1njKyYIl5DzPor50&index=2
https://blog.datumagic.com/p/apache-hudi-from-zero-to-one-110
https://www.youtube.com/watch?v=nGcT6RPjez4
https://www.youtube.com/results?search_query=how+apache+hudi+works+