
What is Databricks ? A Comprehensive Guide to Understanding the Databricks Platform
Beginner's Guide to Databricks Platform: Exploring Its Components, Features, and Why Learning It is Essential

Imagine a small project that begins in a lab, just a spark of an idea. Fast forward, and it's now valued at an impressive $43 billion, showcasing its incredible growth. Databricks has become a major player in the industry, forming partnerships with tech giants like Google Cloud, Amazon Web Services, and Microsoft Azure.
But how did Databricks get to this point?
We will start by going back in time to see how big data technology has evolved and how Databricks began.

The company raised over $500 million in capital last month, bringing its valuation to $43 billion. The wobbly tech markets failed to deter the data analytics firm, as Databricks has been cashing in on the rising popularity of artificial intelligence (AI).
(source : Read the article here)
The Evolution of Big Data Technology

You know, back in the 1990s, there were some big changes happening. The internet was becoming really popular, and that meant more competition because of things like new free trade agreements, computers becoming more common, globalization, and networking. This new way of doing things brought both new chances and new challenges. Businesses were feeling the heat to find valuable insights from all the data they were collecting.
As the demand for practical insights grew stronger, it became clear that robust data management solutions were necessary. Businesses looked for ways to efficiently store and access large volumes of data, which led to the rise of data warehouses
Rise for Data Warehouses
To put it simply, you can think of data warehouses as databases that have extra information added to them, which we call metadata.
The concept of data warehouses first came into use in the 1980s when IBM researchers Paul Murphy and Barry Devlin developed the business data warehouse. American computer scientist Bill Inmon is considered the “father” of the data warehouse due to his authorship of several works, such as the Corporate Information Factory and other topics on the building, usage, and maintenance of the data warehouse.
Inmon wrote the first book, held the first conference, and offered the first classes on data warehouses and is known for his creation of the definition of a data warehouse – “a subject-oriented, nonvolatile, integrated, time-variant collection of data in support of management’s decisions.”
(Source: Read the artucle here)
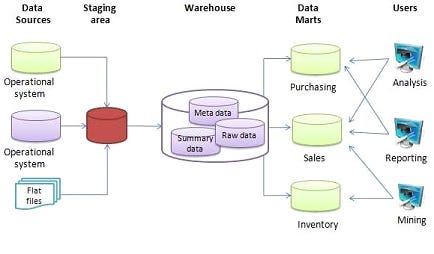
So, imagine data warehouses as these super-sized databases but with extra bells and whistles. Businesses were loving them for a bunch of reasons:
obiviously! Now, they can store and analyze large amounts of data.
They became subject-oriented, which means they focus on specific areas like sales and marketing, unlike databases that handle day-to-day transactions. This allows for more in-depth analysis of data in warehouses.
They can integrate diverse types of data from various sources. (mostly structured and semi structured data)
They become volatile, which means once data is loaded into the warehouse, it remains unchanged and is not subject to constant updates or deletions.
They became time-variant, which means they're built to look at how things change over time. This lets analysts study trends and see how data has changed, helping organizations make smart decisions based on past patterns.
Life was pretty great... until the internet boom happened!

All of a sudden, data warehouses were puzzled about how to deal with unstructured data – you know, the messy stuff like tweets and videos.
They were also dealing with below problem.
High processing time
Inflexible Schemas
High cost
Data governance issues
Fast forward to the 2000s…
The Emergence of Data Lakes

{kind=link}
In the early 2000s, Yahoo made a big move by introducing Hadoop, an open-source framework for managing and processing big data on a large scale. This was a game-changing moment, as it marked the beginning of the data lake era as we know it today.
what is a Data Lake ?
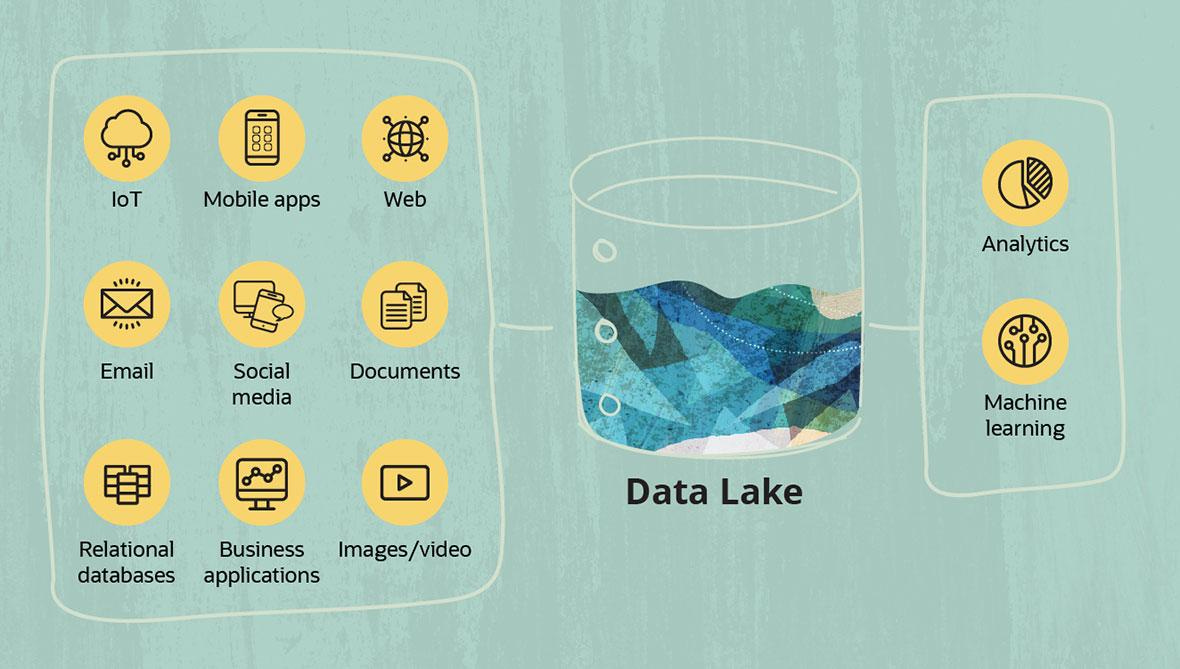
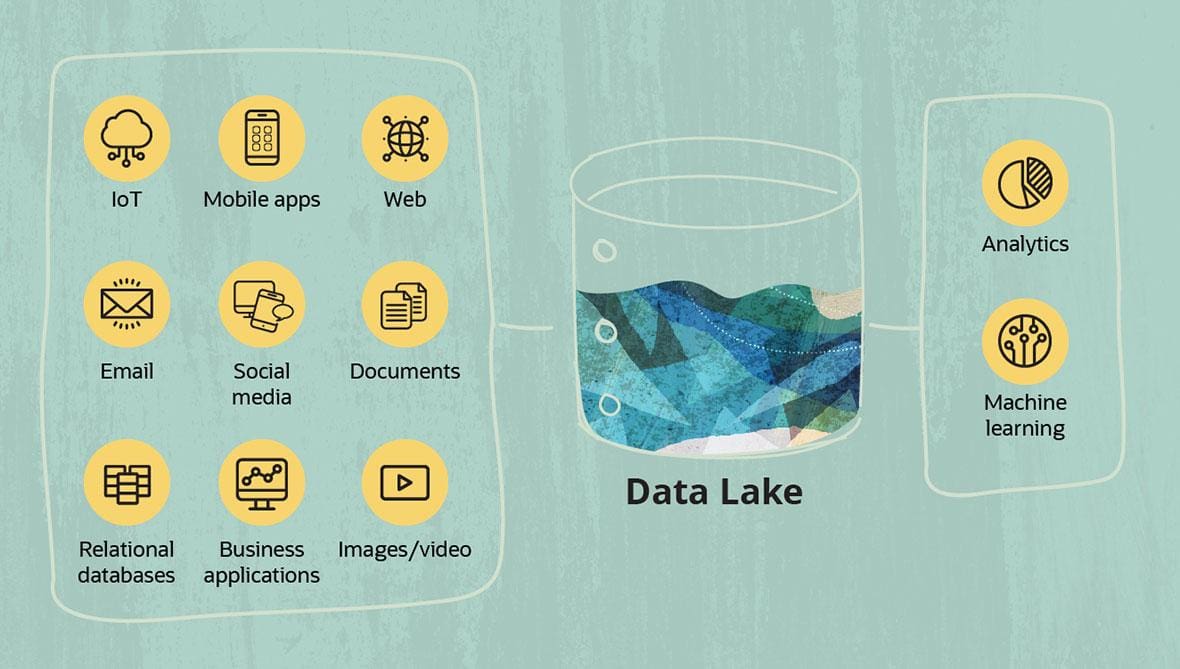
A data lake refers to a central storage repository used to store a vast amount of raw, granular data in its native format. It is a single-store repository containing structured data, semi-structured data, and unstructured data.
So, Data lake is for those who have no clue about the type of data they are collecting😉
{kind=link}
James Dixon, then chief technology officer at Pentaho, coined the term by 2011[4] to contrast it with data mart, which is a smaller repository of interesting attributes derived from raw data.[5] In promoting data lakes, he argued that data marts have several inherent problems, such as information siloing. PricewaterhouseCoopers (PwC) said that data lakes could "put an end to data silos".[6] In their study on data lakes they noted that enterprises were "starting to extract and place data for analytics into a single, Hadoop-based repository."
Why all the hype, though?
It supports structured, semi-structured, and unstructured data
They are a flexible storage platform that can be easily configured for any data model, structure, application, or query. This agility of data lakes allows for the use of multiple and advanced analytical methods to interpret the data.
cloud-based data lakes are cost-efficient
Data lakes are schema-on-demand
They support AI and machine learning
But like everything else, data lakes have their downsides:
Data lakes are at risk of losing relevance and becoming data swamps(unorganized, chaotic data repositories) over time if they are not properly governed.
It is difficult to ensure data security and access control as some data is dumped in the lake without proper oversight.
They do not have any transaction support
Data Governance issues
Poor data reliability
At that time, we were exploring options that could give us the functionalities of both a data warehouse and a data lake.
let’s take a pause for now and shift our focus to Databricks for now.
Enter Databricks: Revolutionizing Data Analytics

Databricks didn't just appear out of nowhere – it came about as Spark evolved. But what's the story behind it? Databricks was created to address the challenges encountered during the deployment of Spark.
From Spark to Cloud: The Journey Begins
So, back in 2010, Spark emerged as an open-source computing engine focused on parallel processing. When Spark showed up, it was a big deal for big data analytics. People quickly saw its potential and started using it with data lakes and distributed cloud computing systems.
Here's where things started to get complicated and challenges began to arise......

Apache Spark started as a research project at the UC Berkeley AMPLab in 2009, and was open sourced in early 2010. Many of the ideas behind the system were presented in various research papers over the years.
(source : Read your Article Here)

Addressing Data Challenges: The Databricks Solution
As Spark became more popular, organizations faced challenges like complex setup processes, competition for resources, and the need for specialized expertise to get the most out of Spark clusters.
Researchers addressed these challenges by initiating another project at UC Berkeley AMPLab: Databricks Cloud, a new cloud platform. This solution, made up of three main parts - The Databricks Platform, Spark, and the Databricks workspace - aimed to provide a unified space for data processing. This meant businesses didn’t have to manage a cluster; everything was taken care of in a managed cloud environment.

Databricks grew out of the AMPLab project at University of California, Berkeley that was involved in making Apache Spark, an open-source distributed computing framework built atop Scala. The company was founded by Ali Ghodsi, Andy Konwinski, Arsalan Tavakoli-Shiraji, Ion Stoica, Matei Zaharia,[4] Patrick Wendell, and Reynold Xin.
(sources : Read the article here , Read the article here )
Fast forward to now, engineers no longer have to worry about managing clusters. They can simply access pre-configured clusters, the Spark compute engine, and a workspace with just a few clicks to run and debug their code. This streamlined process has helped many companies speed up their analytics and save a lot of money.
"For us, Databricks Cloud is all about speed. The platform's rich and simple tools make our deployment a breeze, and its open-source framework enables us to achieve our full potential from a processing and streaming perspective." - Rob Ferguson, director of engineering at Automatic Labs
(Source: Read the article here)
Now we have a basic understanding of how Databricks came into existence
Let's begin our exploration of Databricks by uncovering its official definition from their source.
Databricks is a unified, open analytics platform for building, deploying, sharing, and maintaining enterprise-grade data, analytics, and AI solutions at scale. The Databricks Data Intelligence Platform integrates with cloud storage and security in your cloud account and manages and deploys cloud infrastructure on your behalf.
We will take a closer look at the concepts of "unified" and "open" in the context of Databricks.
Let's start with "unified" first, Databricks is like a one-stop shop for all things data. We can clean up data, change its shape, analyze it, and even train machine learning models, all in the same place. Plus, We can easily collaborate with others and share our work. That's why we say Databricks is unified—it brings everything together.
Now, let's talk about "open." Simply put, Databricks is built on top of open-source tools like Apache Spark and Delta Lake. This means it's not locked into any one technology, and you can use different programming languages like Python, R, Scala, and SQL.
One big deal that came out of Databricks' innovation is the Lakehouse architecture. It's a fancy term for a new way of organizing and using data. The whole Databricks platform is built on top of the Lakehouse architecture. We will dig into that soon, along with all the other cool features that make Databricks so unified.
Let's take a closer look at the technologies that make up the core of Databricks. Essentially, Databricks offers the following capabilities.
Data Lakehouse
Data Engineering
Data Science
Data warehousing
Data governance
Delta sharing
Market place
It's worth noting that these capabilities didn't just emerge overnight; they are the result of years of research. Each capability has been developed using a variety of tools and frameworks, which we will explore individually.
From now on, we will take a closer look at each technology, exploring its background, impact, and advantages step by step.
The Birth of the Lakehouse Architecture
You know, we were hoping for something that could do the job of both a data warehouse and a data lake. And guess what? That's exactly what happened! They created a lakehouse that combines the flexibility, cost-effectiveness, and scalability of data lakes with the management and performance features of a database management system (DBMS). This means you get things like ACID transactions, data versioning, auditing, indexing, caching, and query optimization, all in one. And the best part? It allows for business intelligence (BI) and machine learning (ML) on all your data.
The Lakehouse architecture has indeed played a significant role in unifying Databricks, as we discussed earlier. Its development was not immediate; rather, it was a gradual process that involved the use of technologies created by the Databricks team.
The Lakehouse is built on top of three key technologies: Delta Lake, Delta Engine, and Databricks ML Runtime. While they use other technologies too, these three are particularly important. (read their research paper here: Lakehouse Architecture)
Now, let's look at some of these technologies that contributed to the creation of the data Lakehouse.
Delta: Revolutionizing Data Management
Introduction
In 2017, Databricks introduced Delta, which was the industry's first unified data management system. Delta played a crucial role in transforming Databricks into a 'Lakehouse,' connecting data lakes, data warehouses, and streaming systems.
Challenges Addressed
Before Delta, organizations had the overhead of maintaining three disparate systems: data lakes, data warehouses, and streaming systems. and Delta unified data lakes and data warehouses, streamlining the process of managing and analyzing data in a cloud environment.
Impact and Benefits
Unified Data Management: Delta tables simplify pipelines, ensuring consistency and supporting real-time updates.
Efficient Querying: Delta automates performance tuning, enhancing read efficiency and speeding up queries.
Cost-Efficiency and Scalability: Delta stores data in Amazon S3 for cost-effectiveness and scalability.
Integration with Analytics Platform: Databricks Delta integrates seamlessly with Spark applications, ensuring security and control.
Databricks Delta transforms data warehouses and data lakes into a unified platform, combining the scale and cost-efficiency of data lakes with the reliability, query performance, and low latency of data warehouses and streaming systems. This integration simplifies data architecture, reduces ETL complexity, and enhances data accessibility.
(source: Read the Article Here)
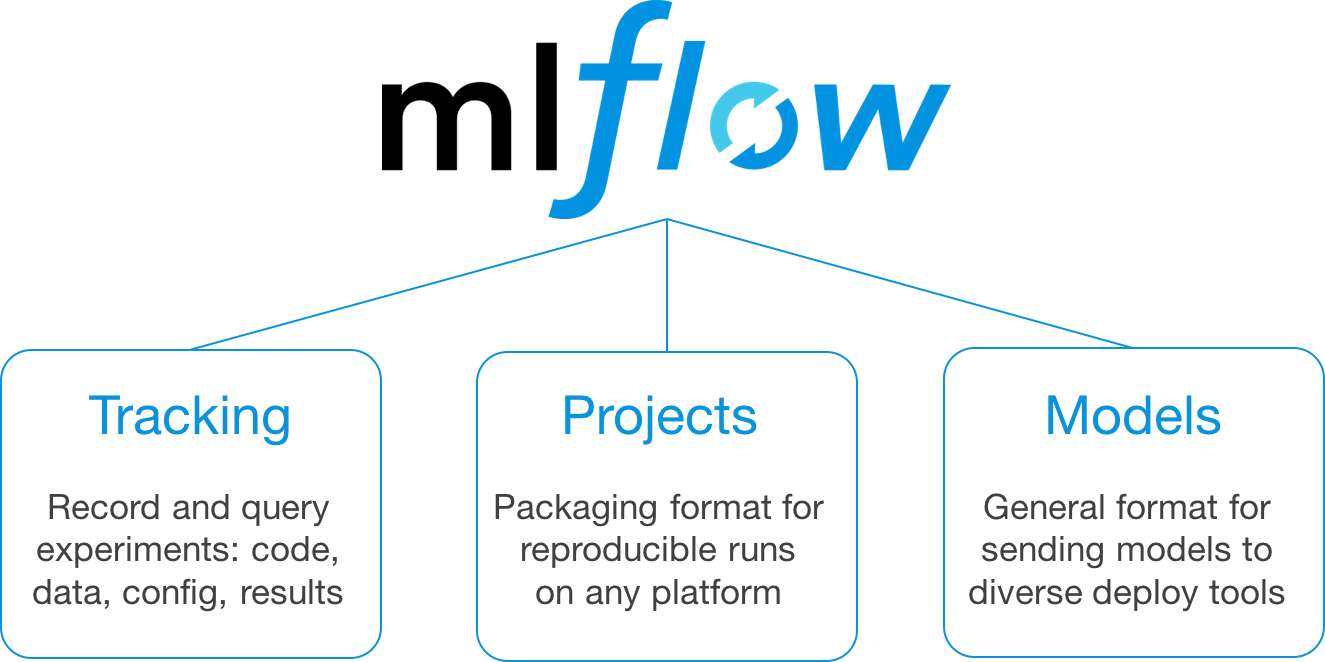
MLFlow: Simplifying Machine Learning Workflow
{kind=link}
Introduction
We all know how important data is for both training and putting machine learning into action. When we build a machine learning model, we start by gathering data, then tweaking features, training the model, testing it out, keeping an eye on its performance, and tracking all the experiments we do. Right now, we're using different tools for each step of this process.
To tackle this issue, Databricks has come up with MLflow. It's an open-source framework that works across different cloud platforms, and it can simplify the whole machine-learning workflow. With MLflow, organizations can bundle up their code so that runs can be reproduced, they can run and compare loads of experiments all at once, they can use whatever hardware or software they like, and they can put their models into action on various platforms. MLflow plays nicely with Apache Spark, SciKit-Learn, TensorFlow, and other open-source machine learning frameworks.
Impact and Benefits
Reproducible Runs: MLflow enables packaging code for consistent runs and easy result replication.
Experiment Comparison: Hundreds of parallel experiments can be executed and compared efficiently.
Flexibility: MLflow allows adaptation to any hardware or software platform.
Model Deployment: Smooth deployment of models to various serving platforms is supported.
“When it comes to building a web or mobile application, organizations know how to do that because we’ve built toolkits, workflows, and reference architectures. But there is no framework for machine learning, which is forcing organizations to piece together point solutions and secure highly specialized skills to achieve AI,” said Matei Zaharia, co-founder and Chief Technologist at Databricks.
Databricks Runtime for ML: Simplifying and Enabling Distributed Deep Learning

Introduction:
So, you know how deep learning has become super popular lately, especially for things like understanding language, sorting out images, and spotting objects? Well, as the amount of data we deal with keeps growing, building these fancy models takes longer and longer because the data gets more complex. That's where distributed deep learning comes in, using tools like TensorFlow, Keras, and Horovod to handle the heavy lifting. But, dealing with all those computers working together can be a headache.
Now, let me tell you about Databricks Runtime for ML. It's like a magic wand for making distributed deep learning way easier. It comes with everything set up already, so you don't have to mess around with configurations. Plus, it plays nicely with all the popular machine learning tools like TensorFlow, Keras, XGBoost, and scikit-learn.
They've even added support for GPUs on platforms like AWS and Microsoft Azure. That means you can tap into the super-fast processing power of GPUs to train your models way quicker.
Impact and Benefits:
Pre-configured Environments: Databricks Runtime for ML offers ready-to-go environments with TensorFlow, Keras, XGBoost, and scikit-learn, eliminating manual setup for model deployment.
GPU Support: Databricks adds GPU support on AWS and Microsoft Azure, speeding up deep learning model training and evaluation.
To derive value from AI, enterprises are dependent on their existing data and ability to iteratively do machine learning on massive datasets. Today’s data engineers and data scientists use numerous, disconnected tools to accomplish this, including a zoo of machine learning frameworks,” said Ali Ghodsi, co-founder and CEO at Databrick
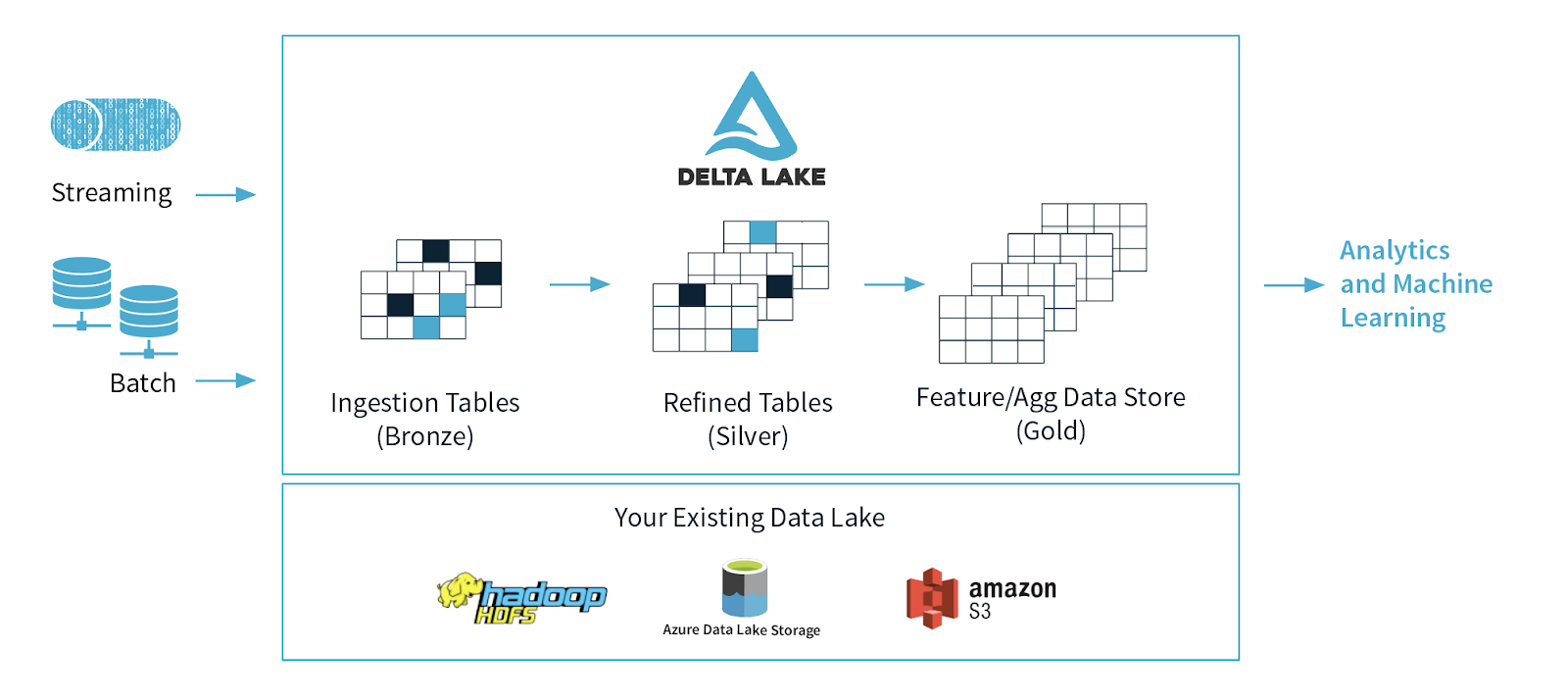
Delta Lake: Resolving Data Lake Unreliability

{kind=link}
Introduction:
Cloud object stores like Amazon S3 and Azure Blob Storage are huge, holding tons of data for millions of customers. They are popular because they let us scale our computing and storage separately. For example, we can store a petabyte of data but only run a query on it for a few hours. Many organizations use these stores to manage big datasets in data warehouses and lakes.
The major "big data" systems like Apache Spark, Hive, and Presto support reading and writing to these stores using file formats like Apache Parquet and ORC. Services like AWS Athena, Google BigQuery, and Redshift Spectrum can also query these systems and formats directly.
However, it's tough to achieve fast and mutable table storage over these systems, which makes it hard to implement data warehousing capabilities. Unlike systems like HDFS or custom storage engines, most cloud object stores are just key-value stores without strong consistency guarantees. Their performance is also different and needs special attention.
Delta Lake solves these problems by introducing an open-source storage format that provides a complete solution for managing structured and unstructured data on top of data lakes.
The core idea of Delta Lake is simple: we maintain information about which objects are part of a Delta table in an ACID manner, using a write-ahead log that is itself stored in the cloud object store.
(Source: Read the article here)
Impact and Benefits:
Structured and Unstructured Data Support: Delta handles both structured and unstructured data, ensuring flexibility without rigid schema requirements.
SQL Queries: Delta enables SQL queries for comprehensive data analysis, leveraging Databricks' analytics capabilities.
Performance Optimization: Databricks Delta includes optimizations for efficient query processing, even with large datasets.
ACID Transactions: Delta supports ACID transactions for data consistency and reliability in operations.
Schema Evolution: Allows for changes to data schema over time without compromising query and analysis capabilities.
Unified Data Management: Delta unifies structured and unstructured data, simplifying data management and analytics by eliminating the need for separate systems.
Efficient streaming I/O, by letting streaming jobs write small objects into the table at low latency, then transactionally coalescing them into larger objects later for performance. Fast “tailing” reads of the new data added to a table are also supported, so that jobs can treat a Delta table as a message bus.
Caching: Because the objects in a Delta table and its log are immutable, cluster nodes can safely cache them on local storage. We leverage this in the Databricks cloud service to implement a transparent SSD cache for Delta tables
So, imagine this: with Databricks Delta Lake, you can say goodbye to the headache of managing separate systems for structured and unstructured data. Everything comes together in one storage layer, making data management and analytics a breeze. It's like having all your data neatly organized under one roof.
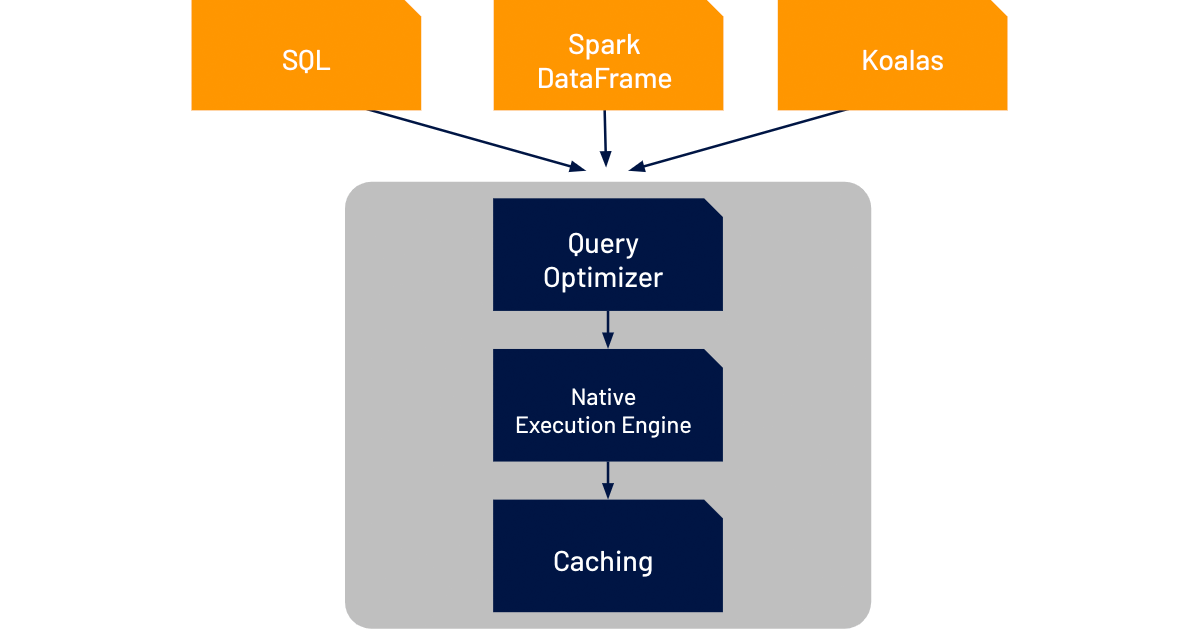
Delta engine: high-performance query engine

{kind=link}
Introduction :
Let's talk about the Delta engine. It's like the high-performance engine for cloud data lakes. Specifically crafted to sync up seamlessly with Delta Lake, this open-source structured transaction layer ensures top-notch quality and reliability in your data lake. Now, Organizations can build curated data lakes that include structured and semi-structured data and run all their analytics on high-quality, fresh data in the cloud.
Benefits:
Accelerated Query Execution: Delta Engine turbocharges query performance, ensuring fast analytics on structured and semi-structured data without the need for data duplication.
Unified Data Analytics Platform: With Delta Engine, organizations can streamline their analytics processes onto a single platform, reducing complexity and costs while supporting diverse data use cases.
Optimized for Cloud Hardware: Built from the ground up to leverage modern cloud infrastructure, Delta Engine maximizes query efficiency, delivering meaningful operational efficiencies.
Expanded Capabilities: Updates to Delta Lake extend its functionality beyond data storage, enhancing how organizations use and consume data, thus amplifying its value.
Lakehouse Architecture

So, in summary, Databricks built their Lakehouse platform using the latest and greatest technologies available, including those mentioned above. They utilized Delta Lake for robust metadata controls, which include support for streaming I/O, time travel for accessing older table versions, and schema enforcement & evolution. The use of Delta Engine ensured high-performance SQL analysis, optimizing query execution for efficient data processing.
Now, we have the best of both worlds – data lakes and data warehouses – seamlessly integrated into one cohesive solution. With Databricks Lakehouse, Now data teams can effortlessly load data from various sources – applications like Salesforce, Marketo, Zendesk, SAP, and Google Analytics, databases like Cassandra, Oracle, MySQL, and MongoDB, and file storage like Amazon S3, Azure Data Lake Storage, and Google Cloud Storage, supporting all their BI and ML use cases.
Nowadays, companies no longer have to segment their data into traditional structured and big data categories for BI and ML tasks. This eliminates the issue of siloed data in data lakes and data warehouses, streamlining processing and ensuring timely and complete results for effective utilization.
(source: Read The full Article Here )
Unified Analytics Platform: The Future of Data
In the era of AI, handling data is just one part of the equation. We also need efficient data processing, analytics (like SQL), and building machine learning models. Until now, we've been juggling different tools for each task. That's where Databricks steps in with Unified Analytics. It merges the worlds of data science and engineering into one platform, making it simpler for data engineers to create pipelines across different systems and prep datasets for model building. At the same time, it empowers data scientists to explore and visualize data, and collaboratively build models. Unified Analytics offers a single engine for preparing high-quality data at scale and training ML models iteratively on the same data. Plus, it fosters collaboration between data scientists and engineers throughout the entire AI lifecycle.
We used to have separate platforms with optimized processes and tools for each. Databricks Lakehouse helped to create a unified space by placing these platforms on top of it. Currently, Databricks supports three platforms.
1, Data Engineering: Streamlining Data Processing
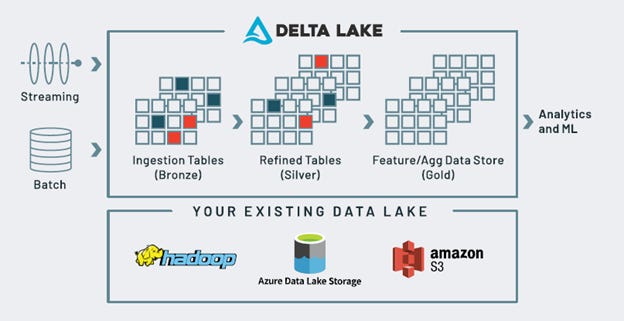
From this point onward, Databricks began crafting optimized platforms for specific use cases.
With the Databricks Data Engineering Platform, We can ingest and transform both batch and streaming data. We can also orchestrate reliable production workflows while Databricks handles infrastructure automatically at scale
Additionally, Databricks offers a wide range of features that simplify the lives of data engineers. Here are some of these features:
Simplified data ingestion: They have developed features like Auto Loader and COPY INTO (We will discuss it later )to simplify data ingestion. Now, we can process files in cloud storage incrementally and automatically, without managing state information, in scheduled or continuous jobs. The system efficiently tracks new files (scaling to billions) without listing them in a directory, and can also automatically infer the schema from the source data and evolve it as it changes over time.
Automated ETL processing: Databricks introduced a framework called DLT (Delta Live Tables). DLT is the first framework to use a simple declarative approach for building ETL and ML pipelines on batch or streaming data. It automates operational complexities such as infrastructure management, task orchestration, error handling and recovery, and performance optimization. With DLT, We can treat our data as code and apply software engineering best practices like testing, monitoring, and documentation to deploy reliable pipelines at scale.
Reliable workflow orchestration: Here, Databricks allows us to manage and orchestrate a variety of workloads throughout their lifecycle, including Delta Live Tables and Jobs for SQL, Spark, notebooks, dbt, ML models, and more.
End-to-end observability and monitoring: The Data Intelligence Platform provides visibility across the data and AI lifecycle, enabling real-time monitoring, data quality management, and trend analysis. Databricks Workflows offer access to dataflow graphs and dashboards for tracking production jobs and Delta Live Tables pipelines, while event logs are available as Delta Lake tables for performance and data quality monitoring.
2, Machine Learning: Accelerating Data Science Workflows
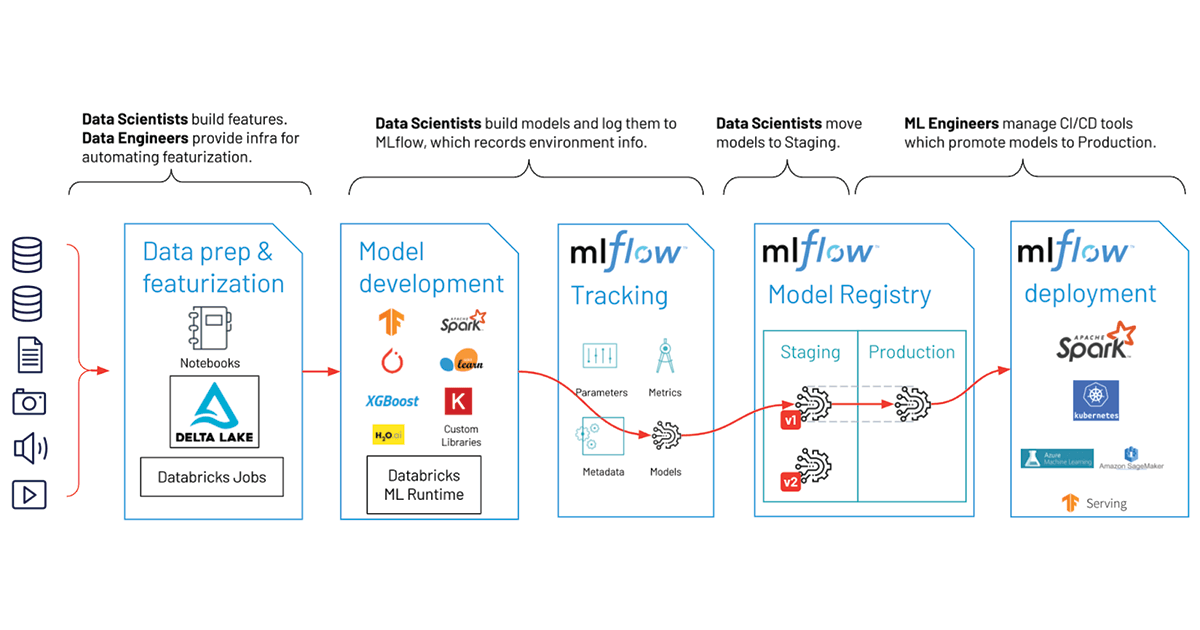
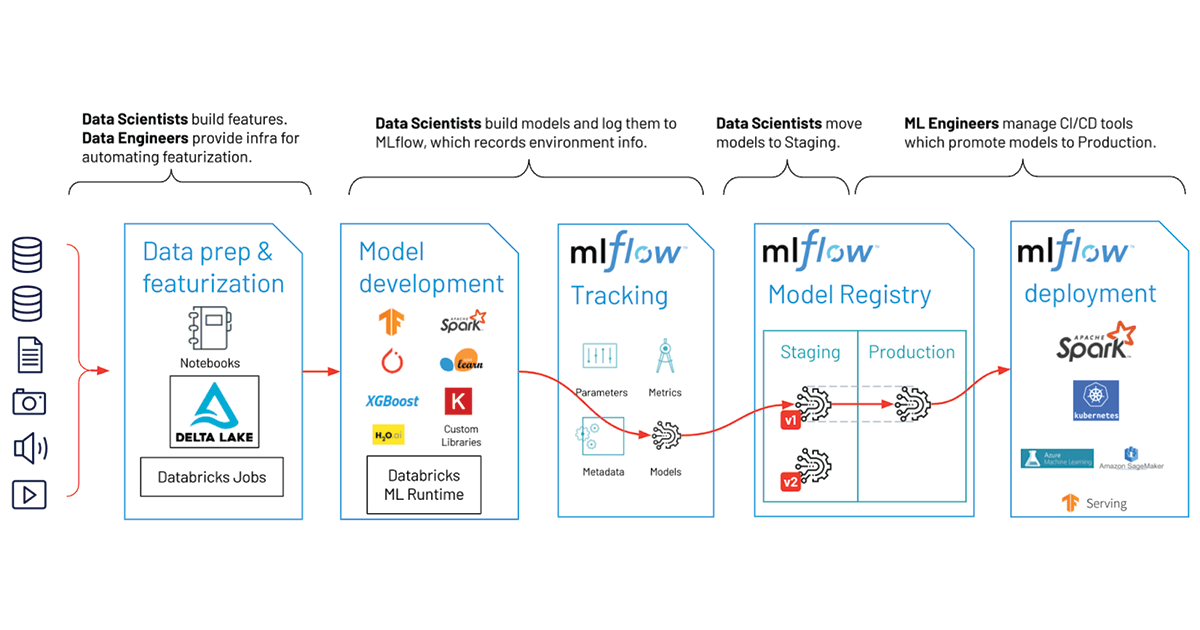{kind=link}
At this stage, Databricks simplified the entire data science workflow. From data preparation to sharing Insights. Here we can have faster access to clean, trustworthy data, along with preconfigured computing resources, integrated development environment (IDE) support, multi-language capabilities, and advanced visualization tools—all designed to offer your data analytics teams the utmost flexibility.
Here are some key components of the ML platform:
Run time for machine learning: Optimized cluster, These clusters are specially optimized for machine learning tasks and are powered by popular frameworks like PyTorch, TensorFlow, and scikit-learn. They're designed to scale seamlessly and are packed with built-in optimizations to deliver unmatched performance, even when dealing with large-scale projects.
Production Ready: With Databricks, we can serve models at any scale with just one click. Plus, you have the option to leverage serverless computing, making the process even smoother.
Model Monitoring: Monitoring model performance and its impact on business metrics in real-time are crucial. Databricks offers end-to-end visibility and lineage from models in production back to source data systems. This helps analyze model and data quality across the full ML lifecycle, allowing you to pinpoint issues before they become a problem.
AutoML: Databricks AutoML allows you to quickly generate baseline models and notebooks. ML.
Managed ML Flow: Just as we learned earlier, being built on top of MLflow, which is widely regarded as the world's leading open-source platform for the ML lifecycle, provides a seamless transition for ML models from experimentation to production. This ensures enterprise-level security, reliability, and scalability, making the entire process much smoother and more efficient.
3, SQL Warehouse: Revolutionizing BI and ETL Workloads

So, this platform is made with folks like data analysts and seasoned business analysts in mind. You know, those who prefer sticking to good old SQL for digging up insights without having to fuss with different tools all the time.
With Databricks SQL, it's like having this serverless data warehouse that's built on this thing called Lakehouse architecture. What's cool is that it lets you handle all your BI and ETL tasks on a big scale, and get this, it's up to 12 times better in terms of price and performance. Plus, you get this unified governance model, support for open formats and APIs, and the best part—you can use the tools you already love without being tied down to any particular vendor. Pretty neat, huh?
Just so you know, here are some mind-blowing features:
We can easily ingest, transform, and orchestrate data from cloud storage to enterprise applications like Salesforce, Google Analytics, or Marketo using Fivetran, all in one click.
It Seamlessly works with popular BI tools like Power BI and Tableau.
It eliminates the need to manage, configure, or scale cloud infrastructure for the Lakehouse, offering unlimited concurrency without disruption for high-concurrency use cases.
Databricks SQL uses the next-generation vectorized query engine Photon(We will learn it later), which provides the best performance.
Now that we have established our Lakehouse and have three distinct and optimized platforms layered on top. But, there is a gap that has to be addressed. At present, we do not have great ways to share data between teams and make sure everything's nice and organized. However, Databricks saw this coming and proactively developed solutions to fill these gaps called Unity catalog.
Unity Catalog: Centralized Data Management

During the data lake era, one of the major headaches we dealt with was administration. While data lakes provided access controls at the file level, we lacked finer-grained control. And when we adopted multi-cloud environments, things got even trickier. We had to manage access permissions across each cloud individually.
But Unity Catalog steps in to tackle these challenges head-on. It offers a centralized metadata repository, standardizes metadata practices, improves data lineage tracking, enhances access control and security measures, makes data more discoverable, and supports collaborative cataloging. It's like having a one-stop solution for all our data administration woes
“Unity Catalog enables us to manage all users across multiple workspaces in one central place, so it makes user management significantly easier. Also, the data lineage feature is out of the box, which helps us identify the downstream dependencies without any manual overheads. In the case of BI data, we can figure out how the BI data is flowing and where the users are putting it using data lineage.”
— Omesh Patil, Data Architect
(source : You can Read The Article Here )
Key features of Unity Catalog include:
Define once, secure everywhere: Unity Catalog provides a centralized platform to manage data access policies that are applicable across all workspaces, ensuring consistent security measures.
Standards-compliant security model: The security model of Unity Catalog adheres to standard ANSI SQL, allowing administrators to grant permissions using familiar syntax within their existing data lake infrastructure. Permissions can be granted at the level of catalogs, databases (or schemas), tables, and views.
Built-in auditing and lineage: Unity Catalog automatically records user-level audit logs, tracking data access activities. Additionally, it captures lineage data to trace the creation and utilization of data assets across various languages.
Data discovery: Unity Catalog facilitates the tagging and documentation of data assets, enabling data consumers to easily locate relevant data through a search interface.
We have established a robust data platform, but Databricks didn't stop there. They continued innovating, introducing a protocol for data sharing called Delta Share, which they open-sourced. Additionally, they launched Databricks Marketplace, a platform for accessing a variety of data, analytics, and AI assets.
Delta Sharing: Facilitating Collaboration Across Organizations
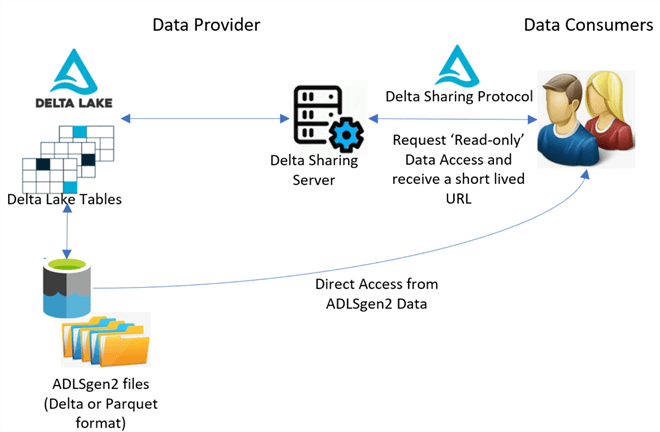
Introduction :
Delta Sharing is a groundbreaking open protocol for securely sharing data across organizations in real time. It is a key addition to the Delta Lake project, supported by Databricks, a consortium of data providers, and major software vendors like AWS, Google Cloud, and Tableau. This marks Databrick’s fifth major open-source project, following Apache Spark, Delta Lake, MLflow, and Koalas, all of which have been generously contributed to the Linux Foundation.
Features:
Open Protocol: Delta Sharing introduces the world's first open protocol for real-time data exchange across organizations, irrespective of the hosting platform.
Integrated within Delta Lake: Seamlessly integrated into the Delta Lake open-source project, Delta Sharing enjoys broad support from various data providers and software vendors.
Freedom from Vendor Lock-in: Delta Sharing liberates organizations from vendor constraints, fostering collaboration across platforms and industries.
Empowering Lakehouse Architecture: Expanding the capabilities of the lakehouse architecture, Delta Sharing facilitates open and collaborative data practices.
Unified Data Sharing Standard: Delta Sharing establishes a standardized protocol for sharing all data types, backed by Delta Lake 1.0 and Linux Foundation support.
Inherent Security Controls: Delta Sharing comes with built-in security measures and manageable permissions to ensure privacy and compliance.
Flexible Data Analysis Options: Delta Sharing empowers organizations to analyze shared data with their preferred tools, supported by industry leaders like Tableau, Nasdaq, Microsoft, and Google Cloud.
Finally, we have the Databricks Marketplace.
Databricks Marketplace

It was created with the idea that there's a high demand for third-party data, but existing data marketplaces often struggle to deliver enough value.
In essence, Databricks Marketplace is an open platform for all our data, analytics, and AI needs, driven by the open-source Delta Sharing standard. This means we can access not only datasets but also AI and analytics assets like machine learning models, notebooks, applications, and dashboards. Importantly, we can do this without being tied to proprietary platforms, dealing with complex ETL processes, or incurring high costs from data replication.
Let's explore how the marketplace has changed consumers and providers, both before and after its introduction.
Challenges for consumers:
Limitations in data discovery: Difficulty in discovering and evaluating datasets due to lack of context.
lock-in: Walled garden environments restrict data exchange and force users to be on the platform, leading to lock-in.
Challenges for providers:
High operational cost: Limited success in increasing sales and lowering operational costs.
No context: Marketplaces often require providers to package datasets without providing enough context, leading to long sales cycles and lost revenue opportunities.
Data replication: Providers incur high compute costs and operational burdens due to proprietary formats and data replication requirements from the marketplace.
After….
Benefits for Data Consumers:
Discover more than just data: It means we can access more than just datasets; we can explore ML models, notebooks, applications, and solutions.
Evaluate data products faster: Pre-built notebooks and sample data can help us quickly evaluate and gain greater confidence that a data product is suitable for our AI, ML, or analytics initiatives.
Avoid vendor lock-in: With this platform, we can significantly reduce the time it takes to gain insights and avoid getting locked into a specific provider. We can effortlessly share and collaborate across various clouds, regions, or platforms. Additionally, we can seamlessly integrate it with your preferred tools and work right where you're most comfortable.
Benefits for Data Providers:
Monetize more than just data: Make money from a wide range of data assets, including datasets, notebooks, ML models, and more, by reaching a broad audience of data consumers.
Reach users on any platform: We can expand to new users and platforms. Connect with a wide ecosystem across clouds and regions. Use native integrations with tools like Excel, PowerBI, and Pandas. Support for AWS, GCP, and Azure.
Share data securely: We can share data sets, notebooks, ML models, dashboards, and more securely across clouds, regions, and data platforms.
Now that we've covered all the technologies and components Databricks uses for its big data platform, let's look at where Databricks stands today and where it's headed.
The Databricks Advantage
Databricks has recently extended its support to three major cloud providers: Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP). This expansion marks a significant milestone in the field of data analytics and AI, as Databricks now offers a unified analytics architecture that seamlessly integrates cloud-powered scalability, robust data engineering capabilities, advanced warehousing solutions, and cutting-edge AI functionalities. This comprehensive approach not only streamlines data workflows but also promotes real-time collaboration among teams, fostering a culture of innovation and efficiency. With Databricks, organizations can now utilize the full potential of these cloud platforms to uncover insights, optimize operations, and drive business success in today's digital landscape.
Here are the main capabilities supported by Databricks at present:
And why should you learn Databricks?
Market share of Databricks in the Big Data Analytics category...

High Demand and Competitive Advantage:
As you can see, Databricks has a market share of 16.38%, which shows how much people want their products and how strong they are compared to other data analytics companies.
Versatility and Future-Proofing:
Databricks is more than just a data platform; it's an investment in your future. Its versatility equips you to handle various data challenges, while its future-proofing capabilities ensure your skills remain relevant in the ever-evolving data landscape. So, if you're looking to thrive in the data-driven world, Databricks is your key to unlocking a successful and fulfilling career journey.
Open-Source Ecosystem:
Databricks is built on top of top open-source projects,
Apache Spark: Core big data processing engine.
Delta Lake: Ensures data reliability with ACID transactions and schema enforcement.
MLflow: Simplifies machine learning lifecycle with experiment tracking and model management.
Delta Sharing: Facilitates secure data sharing across organizations.
Delta Engine: High-performance query engine for real-time analytics.
Koalas: Provides pandas-like API for working with Spark data.
Databricks actively contributes to these open-source projects, fostering innovation and collaboration in the data analytics community.
These projects hold a tremendous amount of market share and aren't likely to become outdated anytime soon.

In conclusion, learning Databricks is not just about acquiring a skill; it's about investing in a future-proof career in the dynamic world of data analytics.
References:
https://en.wikipedia.org/wiki/Data_warehouse
https://corporatefinanceinstitute.com/resources/data-science/data-lake/
https://en.wikipedia.org/wiki/Data_lake
https://blog.nashtechglobal.com/history-of-databricks/
https://www.cidrdb.org/cidr2021/papers/cidr2021_paper17.pdf
https://www.databricks.com/wp-content/uploads/2020/08/p975-armbrust.pdf
#Databricks #DataInnovation #Analytics #AI #MachineLearning #DataScience #DigitalTransformation #FutureOfWork